728x90
SMALL
paper : https://arxiv.org/pdf/2004.04730.pdf
Abstract
- X3D는 tiny 2D 이미지 분류기를 여러가지 축에 따라 점진적으로 확장하는 것이다.
- multiple network axes, in space, time, width and depth 등
- 간단한 stepwise network expansion 방법이 적용되었다.
- 한번의 step에 single axis를 확장
- X3D를 구체적인 target complexity로 확장하기 위해 점직적인 forward expansion을 하고 이어서 backward contraction을 수행한다.
- 가장 의미있는 발견은 high spatiotemporal resolution을 가진 네트워크가 폭과 매개변수 측에서 매우 가볍고, 잘 수행된다는 점이다.
Introduction
- video recognition 영역에서 neural network는 주로 2D image architecture를 space time으로 확장하면서 수행된다.
- 전형적으로 이러한 확장은 2D network로부터 temporal 축을 따라 수행된다.
- 시간 축을 따라 확장하면 일반적으로 정확도는 증가하지만 연산량이 많다는 점에서 최선책이라고는 할 수 없다.
- 본 논문은 연산량과 정확도의 trade-off 관계에서 low-computation에 초점을 맞춘다.
- 디자인은 image recognition에서 개발된 mobile-regime을 베이스로 한다.
- 핵심 아이디어는 시간 축이 아닌 다른 축을 확장하면서도 정확도가 빠르게 올라갈 수 있다는 것이다.
- 본 논문에서 tiny한 image base의 2D 모델을 다양한 possible한 축을 따라 확장하면서 spatiotemporal로 확장한다.

- 확장하는 과정은 architecture가 desired computational budget에 도달할때까지 반복된다.
- 본 network는 depth, resolution, width를 확장하는 image ConvNet 디자인으로부터 영감을 받았다.
- X3D는 small, medium, large로 complexity 정도에 따라 나뉜다.
- 가장 놀라운 발견은 매우 시공간 해상도와 깊이만 확장하여 만들어진 매우 얇은 비디오 모델이 매우 가벼우면서도 우수한 성능을 발휘할 수 있다는 것이다.
Related Work
Spatiotemporal (3D) networks
- 비디오 인식 architecture는 시간적 차원으로 이미지 분류 네트워크를 확장하고 공간 특성을 보존함으로써 설계된다.
- SlowFast의 경우에는 Fast pathway를 얇게 하여 연산량을 줄일 수 있으나 isolation이 낮다.
X3D Networks
- 비디오 architecture는 이미지 모델의 직접적인 temporal 확장에 기반했기 때문에 유사한 진전이 관찰되지 않았다.
- “2D에서 3D로 확장할때, 고정된 축이 좋을까? 아니면 다른 축을 따라 확장하거나 축소하는 것이 좋을까?
Questions
- 3D network에서 가장 좋은 temporal sampling strategy는 무엇일까
- 짧은 지속시간 클립의 빠른 샘플링 VS 긴 입력 지속시간의 sparse한 샘플링
- heavy한 layer를 가진 네트워크 VS light한 layer를 가진 네트워크
- ResNet block에서 network width를 global하게 증가시키는 것 VS inner(bottleneck) width를 증가시키는 것
Basis instantiation
- 시공간으로 확장되는 기준선의 역할을 하는 기본 네트워크 구조인 X2D를 설명하는 것으로 시작한다.
- 기본 basis network는 ResNet구조와 single frame을 가진 SlowFast net의 Fast pathway 디자인을 따른다.
- X2D는 single frame을 input으로 사용하면서 network width가 fast pathway와 비슷함으로 Slow pathway로 해석 될 수 있다.
- image net 디자인을 따르는 전형적인 3D ConvNet보다 가볍다.
- X2D가 6가지 축을 따라 확장된다.
Expansion operations
- X-Fast : frame-rate를 증가시킴으로써 temporal activation size를 확장
- X-Temporal : 긴 temporal clip을 샘플링하고 frame-rate를 증가시킴으로써 temporal size를 확장
- X-Spatial : spatial sampling resolution을 확장
- X-Depth : layer의 개수를 증가시킴으로써 network depth를 확장
- X-Width : 모든 layer의 채널 수를 확장
- X-Bottleneck : 각 residual block의 inner channel width를 확장
Expanded networks
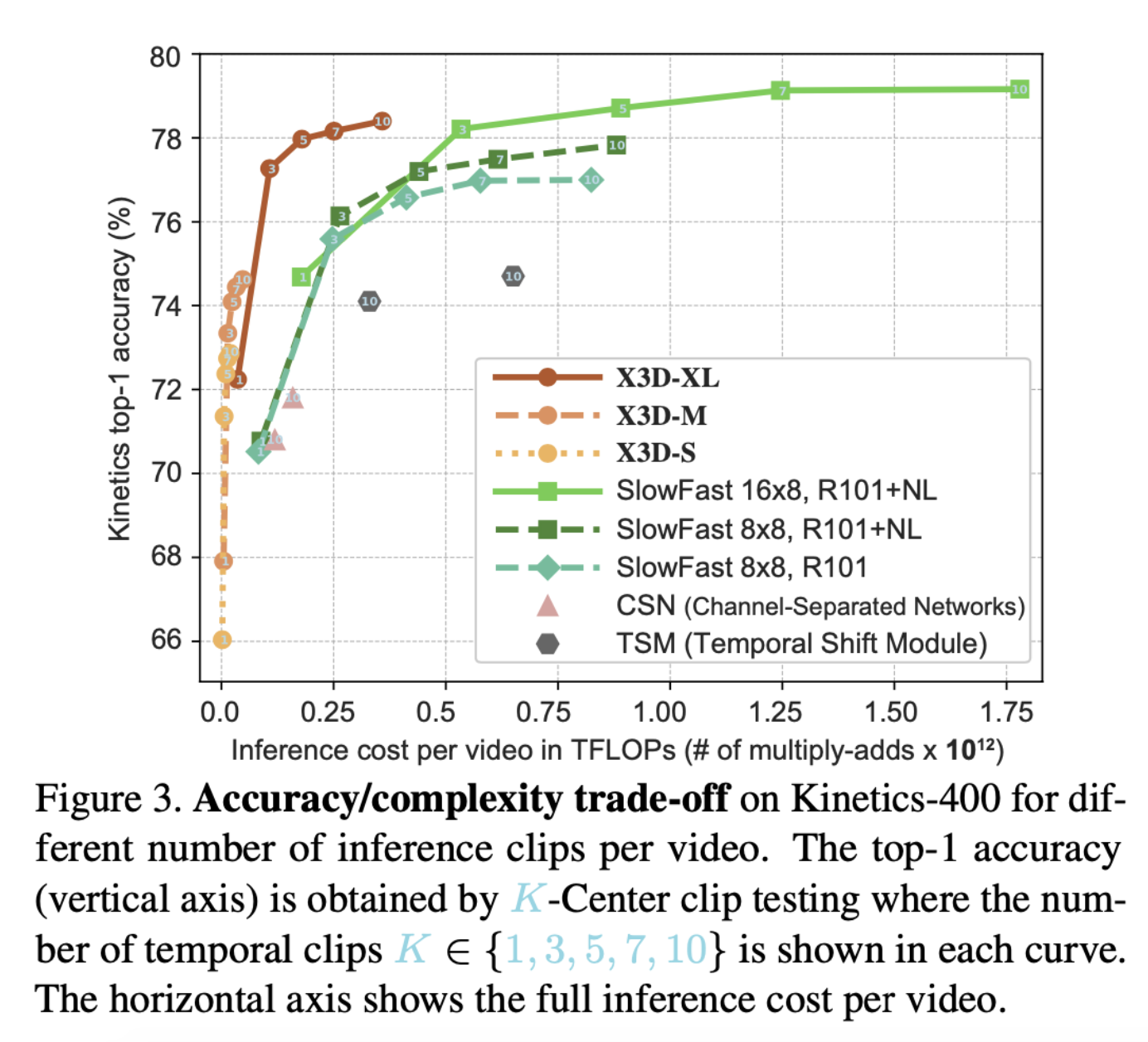
- accuracy/complexity trade-off 커브 on Kinetics-400
- X2D부터 확장 시작
- 여러 후보 중 한가지 축을 확장하는 것은 정확도를 높인다.
- → multiple axes를 취하는 것에 대한 motivation이 된다.
- expansion algorithm에 의해 첫번째로 선택된 축은 temporal이 아니다.
- 첫번째 축이라고 예상했던 temporal axis는 두번째로 선택되었다.
- 세번째 단계는 spatial resolution을 높인다. 그리고 그래프에서 흥미로운 패턴을 보이기 시작한다. 그리고 깊이를 증가시킨다.
Result
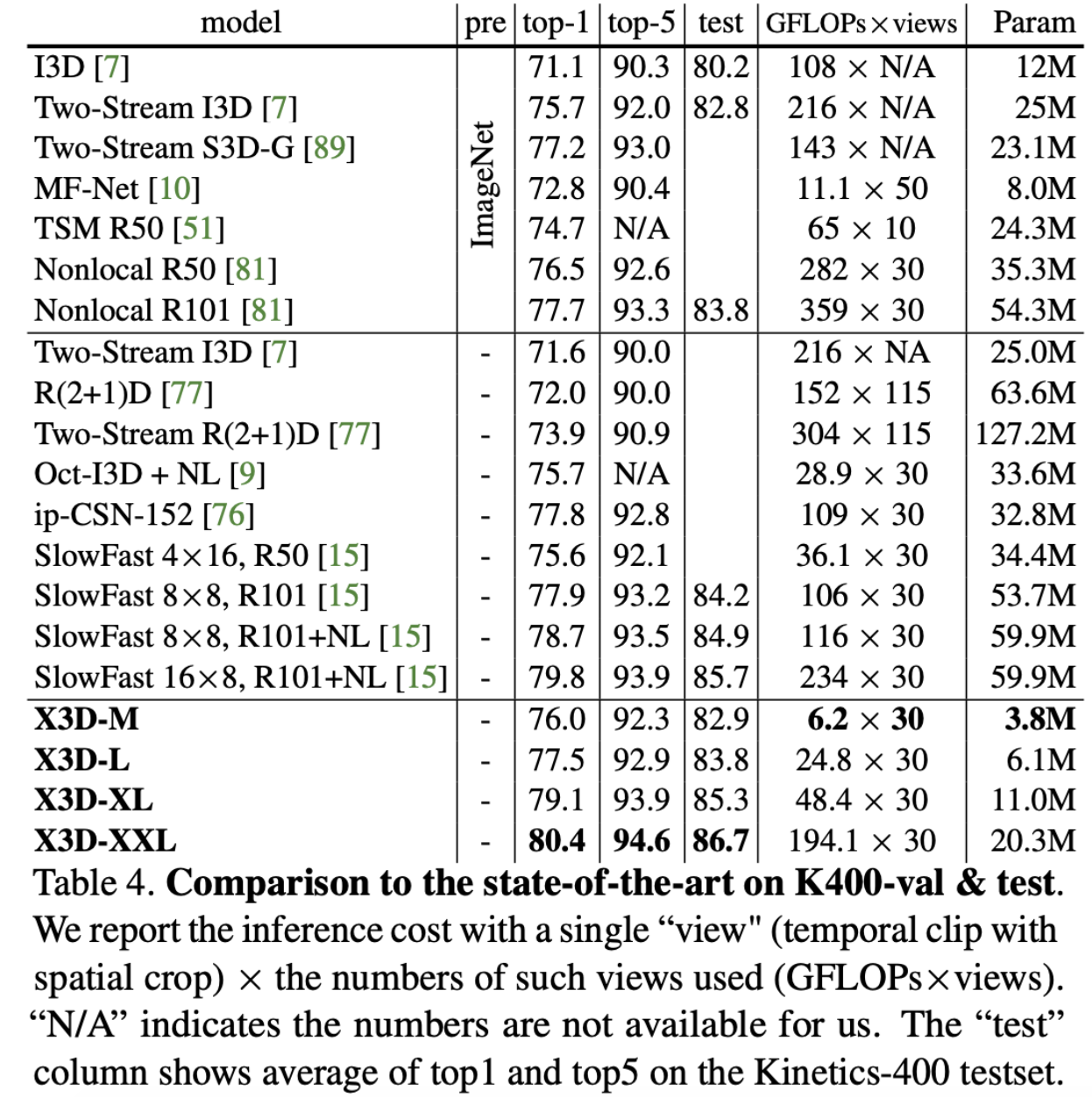
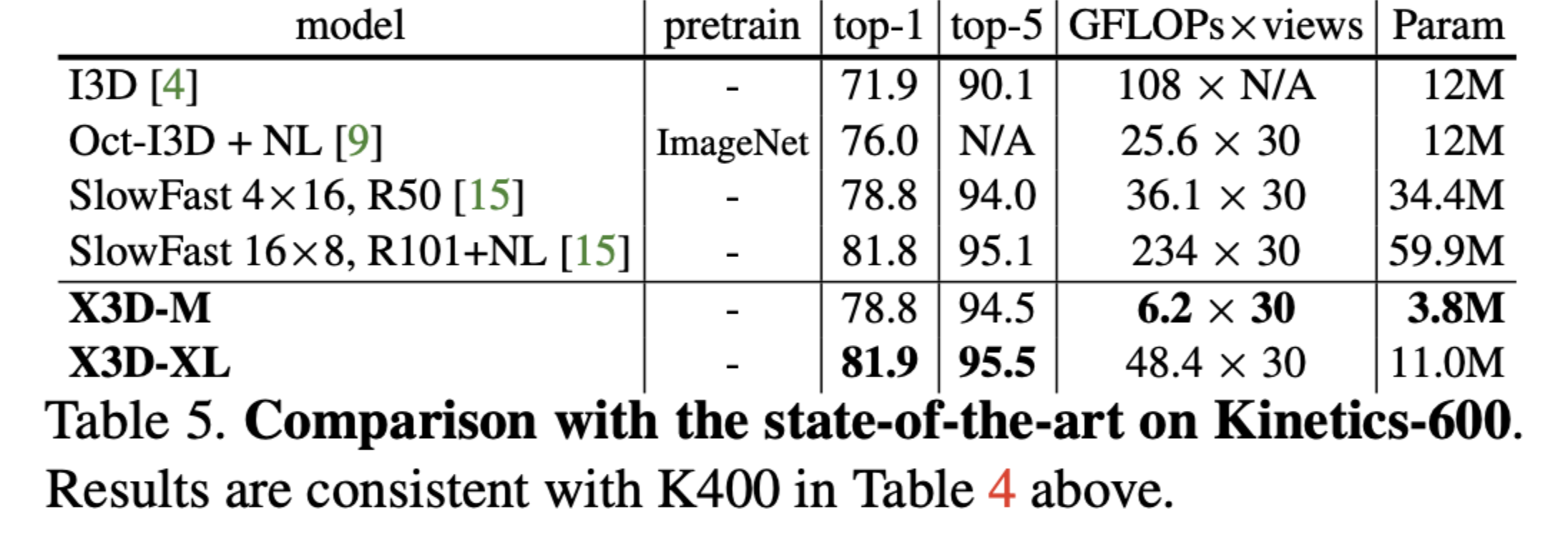
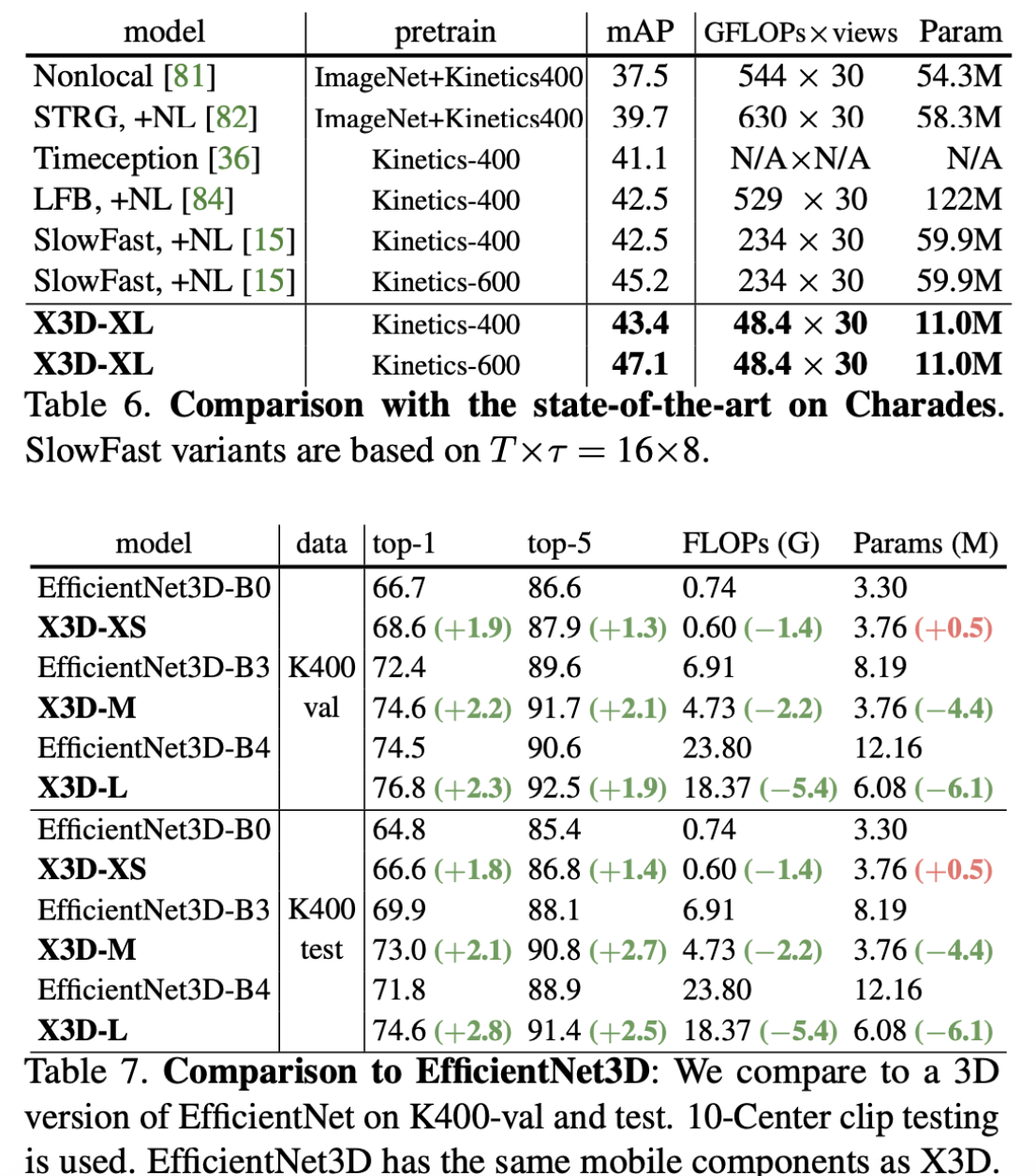
Conclusion
- 본 논문에서 소개된 X3D는 tiny spatial network에서 점진적으로 확장된 spatiotemporal 구조이다.
- 여러가지의 candidate axis가 computation/accuracy trade-off 아래에서 확장에 사용되었다.
- 놀라운 발견은 점진적 확장을 통해 얻은 얇은 channel dimension, high spatiotemporal resolution을 가진 네트워크가 video recognition에서 효과적일 수 있다는 것이다.
LIST
'CNN 논문' 카테고리의 다른 글
| [논문 리뷰] Learning Spatio-Temporal Representation with Pseudo-3D Residual Networks (0) | 2022.01.05 |
|---|---|
| [논문 리뷰] Learning Spatiotemporal Features with 3D Convolutional Networks (0) | 2022.01.04 |