728x90
SMALL
paper : https://arxiv.org/pdf/1711.10305.pdf
Abstract
- Convolutional Neural Networks(CNN)은 이미지 분류 문제에서 powerful한 모델로 여겨져왔다.
- 몇 연구에서 비디오 데이터에 3D convolution을 수행하는 것이 spatial(공간)과 temporal(시간) 정보를 저장하는 것에 의미있는 것임을 보였다.
- 그러나 3D CNN을 수행하는 것은 연산량이 매우 많고 메모리가 많이 필요하다.
- 그래서 생길 수 있는 의문점은 다음과 같다.
- “3D CNN을 수행할때 2D network의 정보를 재사용하면 되지 않을까?”
- 해당 논문에서는 3 x 3 x 3 convolution을 1 x 3 x 3 convolution filter와 3 x 1 x 1 convolution filter로 나누어 residual learning의 bottleneck building block에 적용하는 구조를 고안했다.
- 그리고 Pseudo-3D Residual Net(P3D ResNet)이라는 새로운 구조를 제안한다.
- P3D ResNet은 Sports-1M 데이터셋에 대하여 더 나은 결과를 보인다.
Introduction
- 최근들어 CNN은 특히 이미지 영역에서 visual representation을 학습하는 능력이 있음이 입증됐다.
- 비디오 데이터의 경우 Spatio-temporal 정보를 encoding하는 자연스러운 방법은 2D에서 3D CNN으로 convolution kernel을 연장시키는 것이다.
- 그러나 3D CNN은 2D CNN에 비해 연산량이 매우 많고 모델 사이즈도 매우 크다.

- 11개 layer를 가진 C3D 네트워크와 152 layer가진 2D ResNet을 비교했을때, layer 개수의 차이가 큼에도 2D ResNet의 모델 사이즈가 작다는 것을 알 수 있다. (= 3D CNN의 모델 사이즈가 매우 크다)
→ Deep한 3D CNN의 train을 어렵게 만든다.
- 그리고 더 중요한것은 Sports-1M 데이터에 대하여, 2D ResNet-152의 fine-tunning 과정을 거친 것이 C3D보다 더 좋은 정확도를 가질 수 있다는 것이다.
- 다른 대안적인 방법에는, pooling 구조를 활용하거나 RNN을 활용하는 것이 있다.
- 해당 논문에서는 위의 여러가지 문제들은 bottleneck building block으로 해결함을 보여준다.
→ 3 x 3 x 3 convolutional layer를 1 x 3 x 3 , 3 x 1 x 1 convolutional layer로 대체함으로써
→ 모델 사이즈도 감소
- P3D ResNet에서 temporal connections은 모든 단계에서 이루어진다.
P3D Blocks and P3D ResNet
- 먼저 3D convolution이 자연스럽게 2D spatial convolution과 1D temporal convolutional filter로 분해된다는 것을 정의한다.
- 그리고 spatial과 temporal convolutional filter를 모두 처리하는 bottleneck building block을 고안했다.
- ResNet 구조를 기반으로 P3D block을 구성하는 Pseudo-3D Residual Net을 제안했다.
- performance와 time efficiency 측면에서 실험을 했다.
3D Convolutions
- 3 x 3 x 3 convolutional filter가 1 x 3 x 3, 3 x 1 x 1 로 분해된 convolution을 유사 3D CNN이라고 할 수 있으며 Pseudo 3D CNN이라고 부른다.
- 위처럼 분해하면 모델 사이즈를 확연히 줄일 뿐만 아니라, 이미지 데이터로부터 2D CNN을 적용하여 pre-training 하여 3D CNN에 활용할 수 있다.
Pseudo-3D Blocks
Residual Units
- Residual Units : ResNet은 많은 stacked Residual Units을 구성한다.
- 각각의 Residual Unit은 다음과 같이 나타낸다.
- h(x_t)는 identity mapping이고, F는 non-linear residual function이다.
- 따라서 다음과 같이 나타낼 수도 있다.
- ResNet의 메인 아이디어는 input x_t를 참조하여 추가적인 residual function F를 학습하는 것이다.
- 그리고 그것은 shortcut connection을 통해 이뤄진다.
P3D Blocks design
- S : spatial dimension
- T : temporal dimension
- 첫번째 이슈 : 2D filter(S)가 1D filter(T)에 직접적 혹은 간접적으로 영향을 미치는지
- 두번째 이슈 : 두 종류의 filter가 final output에 직접적 혹은 간접적으로 영향을 미치는지
- 위의 두가지 이슈를 고려하여 세가지 디자인이 나왔다.
- (1) P3D-A
- (2) P3D-B
- (3) P3D-C
Bottleneck architectures
- 채널을 축소하고 feature를 추출하고 다시 채널을 증가시키는 방법인 bottleneck 구조는 convolution parameter 수를 감소시킨다.
참고한 블로그 : https://coding-yoon.tistory.com/116
[딥러닝] DeepLearning CNN BottleNeck 원리(Pytorch 구현)
안녕하세요. 오늘은 Deep Learning 분야에서 CNN의 BottleNeck구조에 대해 알아보겠습니다. 대표적으로 ResNet에서 BottleNeck을 사용했습니다. ResNet에서 왼쪽은 BottleNeck 구조를 사용하지 않았고, 오른쪽은..
coding-yoon.tistory.com
Pseudo-3D ResNet
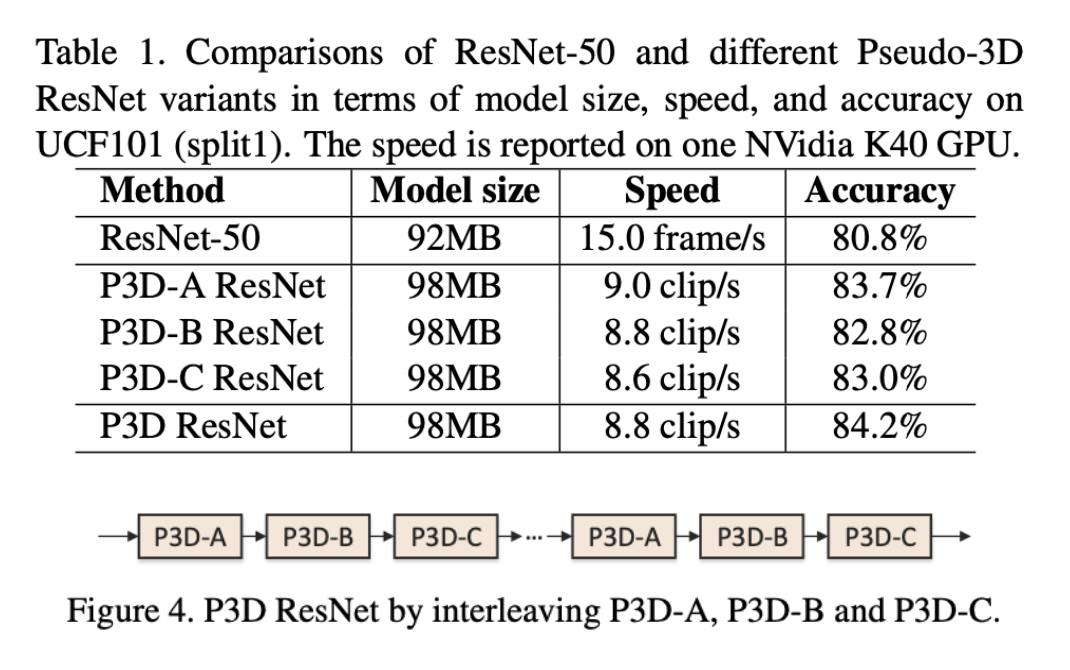
- 세가지 P3D block에 대한 performance와 time efficiency
- 최종버전인 mixing된 버전의 P3D block이다.
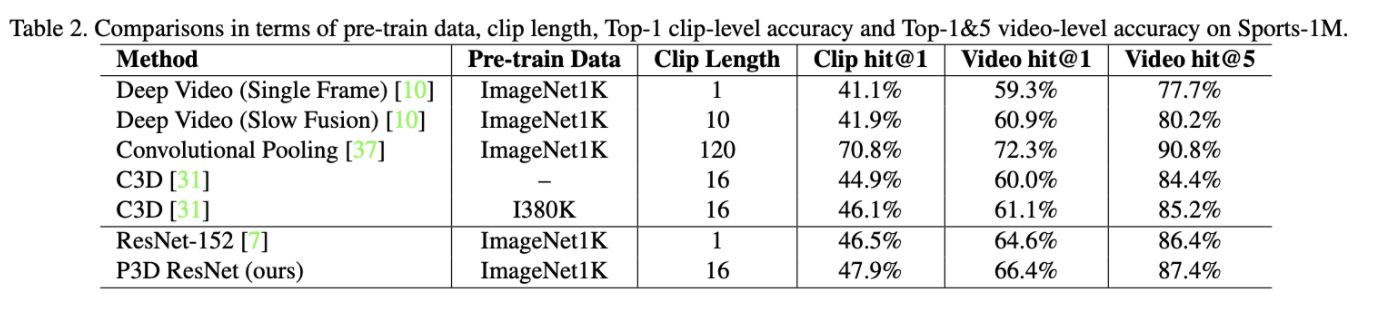
Sports-1M에 대하여 Deep video, convolutional pooling, C3D와 비교
Conclusion
- Deep network에서 spatio-temporal video representation을 학습하는 Pseudo-3D Residual Net구조를 제안했다.
- 3D convolution을 2D filter와 1D filter로 분해하는 단순화 과정을 거쳤다.
- 여러가지 bottleneck 구조를 제안했다.
LIST
'CNN 논문' 카테고리의 다른 글
| [논문 리뷰] X3D: Expanding Architectures for Efficient Video Recognition (0) | 2022.01.05 |
|---|---|
| [논문 리뷰] Learning Spatiotemporal Features with 3D Convolutional Networks (0) | 2022.01.04 |